▶ AI 시스템은 신뢰할 수 없는 데이터에 노출되면 오작동할 수 있으며, 공격자는 이 문제를 악용하고 있다.
▶ 새로운 지침에는 이러한 공격 유형과 완화 방법이 문서화 되어 있다.
▶ AI를 잘못된 방향으로부터 보호하는 완벽한 방법은 아직 존재하지 않으며, AI 개발자와 사용자는 달리 주장하는 사람을 경계해야 한다.
공격자는 인공지능(AI) 시스템을 고의로 혼동을 주거나 심지어 ‘독’을 주입하여 오작동을 일으킬 수 있다. 그러나 개발자가 사용할 수 있는 완벽한 방어 수단은 없는 형편이다. 미국 상무부 산하 국립표준기술연구소(NIST)는 최근 공개한 보고서에서 인공지능(AI)과 머신러닝(ML)의 취약점에 대해 경고했다.
“적대적 머신러닝: 공격 및 완화에 대한 분류와 용어(NIST.AI.100-2)[
Adversarial Machine Learning: A Taxonomy and Terminology of Attacks and Mitigations (NIST.AI.100-2)]”라는 제목의 이 보고서는 AI 개발자와 사용자가 예상할 수 있는 공격 유형과 이를 완화하기 위한 접근 방식에 대해 소개하고 있다.
저자 중 한 명인 NIST 컴퓨터과학자 아포스톨 바실레프(Apostol Vassilev)는 “우리는 모든 유형의 AI 시스템을 고려한 공격 기술과 방법론에 대한 개요를 제공하고 있다. 또한, 문헌에 보고된 현재의 완화 전략을 설명하지만, 이러한 가용한 방어 수단이 현재의 위험을 완전히 완화한다는 보장은 할 수 없다"며 커뮤니티에 더 강력한 방어 수단을 마련할 것을 촉구했다.
AI 시스템은 차량 운전에서부터 의사의 질병 진단 지원, 온라인 챗봇을 통한 고객과의 대화에 이르기까지 다양한 기능을 수행한다. 이러한 작업을 수행하는 방법을 배우기 위해, AI는 방대한 양의 데이터를 학습한다. 예를 들어, 자율주행 차량에는 도로표지판이 있는 고속도로와 거리의 이미지가 표시될 수 있으며, 대규모 언어 모델(LLM) 기반의 챗봇은 온라인 대화 기록이 노출될 수 있다. 이러한 데이터는 AI가 주어진 상황에서 어떻게 대응할지 예측하는 데 도움이 된다.
한 가지 문제는 데이터 자체를 신뢰할 수 없다는 것이다. 데이터의 소스는 웹사이트나 대중과의 상호작용의 결과물 일 수 있다. AI 시스템이 학습하는 기간과 그 이후에도 AI가 실제 세계와 상호작용하여 행동을 계속 개선하는 동안 악의적인 공격자가 데이터를 손상시킬 수 있는 기회는 많다. 이로 인해 AI가 바람직하지 않은 방식으로 작동할 수 있다. 예를 들어, 챗봇은 신중하게 조작된 악의적인 프롬프트에 의해 방호책을 우회할 경우 욕설이나 인종차별적인 언어로 응답하는 방법을 학습할 수 있다.
AI를 학습시키는 데 사용되는 데이터 세트가 방대하여 사람이 성공적으로 모니터링하고 필터링할 수 없기 때문에, 아직까지 AI를 잘못된 방향으로부터 보호할 수 있는 완벽한 방법은 없다. NIST 보고서는 개발자 커뮤니티를 돕기 위해 AI 제품이 받을 수 있는 공격의 유형과 피해를 줄이기 위한 적절한 접근 방식에 대한 개요를 제공한다.
이 보고서에서는 회피, 중독, 프라이버시, 남용 등 4가지 주요 적대적 머신러닝 공격 유형을 강조하고 있다. 또한, 공격자의 목표와 목적, 역량, 지식 등 여러 기준에 따라 공격 유형을 분류하고 있다.
회피 공격(Evasion attack)은 AI 시스템이 배포된 후 발생하는 공격 유형으로, 입력값을 변경하여 AI가 잘못된 의사결정을 하도록 시도한다. 입력 공격이라고도 한다. 예를 들어, 정지표지판에 표시를 추가하여 자율주행 차량이 이를 속도제한표지판으로 잘못 인식하게 하거나, 차선 표시를 혼동하게 만들어 차량이 도로를 벗어나도록 하는 등의 공격이 이에 해당한다.
중독 공격(Poisoning attack)은 공격자가 AI 모델의 학습 단계에서 의도적으로 악의적인 데이터를 주입하여 발생한다. 예를 들어, 챗봇이 부적절한 발언을 하도록 악의적인 행위자에 의해 학습되어 욕설, 인종차별 발언을 남발하도록 하는 것이다.
회피 공격과 프라이버시 공격은 AI 방어에 더욱 복잡한 계층을 추가한다. 배포 중에 발생하는
프라이버시 공격(Privacy attack)은 AI가 학습한 데이터 중 민감한 정보를 추출하여 이를 오용하려는 시도다. 공격자는 챗봇에게 합법적인 다양한 질문을 한 후, 그 답변을 통해 모델을 리버스 엔지니어링하여 약점을 찾거나 소스를 추측할 수 있다. 이러한 온라인 소스에 원치 않는 예시를 추가하면 AI가 부적절하게 행동할 수 있으며, 사후에도 학습된 행동을 학습하지 않도록 하기 어렵다.
남용 공격(Abuse attack)은 웹페이지나 온라인 문서와 같은 합법적인 소스에 잘못된 정보를 삽입하여 AI가 이를 흡수하는 것을 포함한다. 남용 공격은 중독 공격과 달리 합법적이지만 손상된 소스에서 잘못된 정보를 AI에 제공하여 AI 시스템의 의도된 용도를 변경하려는 시도다.
이 보고서의 공동저자인 노스이스턴 대학교(Northeastern University) 알리나 오프레아(Alina Oprea) 교수는 “이러한 공격은 대부분 매우 쉽게 실행할 수 있으며, AI 시스템에 대한 최소한의 지식과 제한된 공격 능력만 있으면 된다"면서 "예를 들어, 중독 공격은 전체 학습 세트의 극히 일부에 해당하는 수십 개의 학습 샘플을 제어하여 실행할 수 있다”라고 지적했다.
로버스트 인텔리전스(Robust Intelligence)의 연구원인 앨리 포다이스(Alie Fordyce)와 하이럼 앤더슨(Hyrum Anderson)을 포함한 저자들은 이러한 공격 유형을 각각 하위 범주로 분류하고 이를 완화하기 위한 접근 방식을 추가했지만, 이 간행물에서는 지금까지 AI 전문가가 적대적 공격에 대해 고안한 방어책이 불완전하다는 점을 인정하고 있다. 바실레프는 AI 기술을 배포하고 사용하려는 개발자와 조직이 이러한 한계를 인식하는 것이 중요하다고 강조했다.
그는 “AI와 머신러닝이 상당한 진전을 이루었음에도, 이러한 기술은 공격에 취약하여 심각한 결과를 초래할 수 있다"며 "AI 알고리즘을 보호하는 데는 아직 해결되지 않은 이론적 문제가 있다. 누군가 달리 주장하는 사람은 ‘뱀 기름을 파는 것’이다”라고 지적했다.
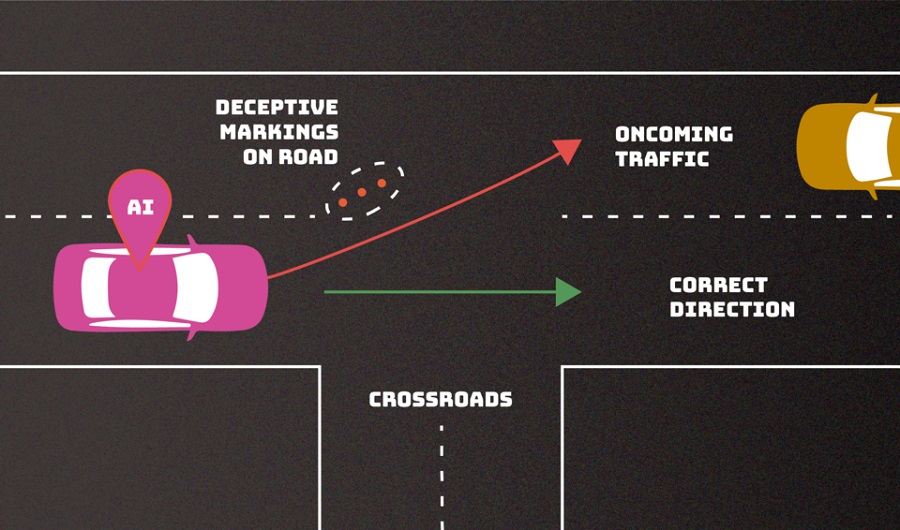 이 예에서는 도로의 잘못된 표시가 무인 자동차를 잘못 인도하여 마주 오는 차량으로 방향을 틀게 할 수 있다. 이 "회피(evasion)" 공격은 예상되는 공격 유형과 이를 완화하기 위한 접근 방식을 설명하기 위해 NIST에서 발행한 새로운 간행물에 설명된 수많은 적대적 전술(Adversarial tactics) 가운데 하나다. [출처=N. Hanacek/NIST]
이 예에서는 도로의 잘못된 표시가 무인 자동차를 잘못 인도하여 마주 오는 차량으로 방향을 틀게 할 수 있다. 이 "회피(evasion)" 공격은 예상되는 공격 유형과 이를 완화하기 위한 접근 방식을 설명하기 위해 NIST에서 발행한 새로운 간행물에 설명된 수많은 적대적 전술(Adversarial tactics) 가운데 하나다. [출처=N. Hanacek/NIST]
AEM_Automotive Electronics Magazine
<저작권자(c)스마트앤컴퍼니. 무단전재-재배포금지>





